
RAG 런타임 단계
RAG 사전 준비 단계에 이어, 이번 아티클에서는 런타임 단계에 대해서 설명드리려고 해요. 런타임 단계는 Retriever(검색기), Prompt(프롬프트), LLM(Large Language Model), Chain(체인 생성)의 네 단계로 이루어집니다.
RAG는 크게 8단계의 프로세스로 구성되는데요, Document Loader(도큐먼트 로드), Text Splitter(텍스트 분할), Embedding(임베딩), Vector Store(벡터 스토어 저장)의 사전 준비 단계와 Retriever(검색기), Prompt(프롬프트), LLM(Large Language Model), Chain(체인 생성)의 런타임 단계로 나뉘어집니다. 그리고 이번 아티클에서는 사전 준비 단계에 대해서 설명드리려고해요.
런타임 단계
Retriever
Retriever 검색기
RAG 시스템의 다섯 번째 단계이자 런타임 단계의 첫 번째 단계는 바로 검색기 단계입니다. 저장된 벡터 데이터베이스에서 사용자의 질문과 관련된 문서를 검색하는 과정이죠. 검색기 단계는 RAG 시스템의 전반적인 성능과 직결되는 중요한 과정인데요, 사용자 질문에 가장 적합한 정보를 신속하게 찾아내는 것이 이 단계의 목표이기 때문입니다. 효과적인 검색 과정을 통해 답변에 필요한 정보만을 추출함으로써 시스템 자원의 사용을 최적화하고, 불필요한 데이터 처리를 줄일 수 있는 단계입니다.
검색기는 RAG 시스템에서 정보 검색의 질을 결정하는 핵심적인 역할을 하고 있어요. 효율적인 검색기 없이는 대규모의 데이터베이스에서 관련 정보를 신속하고 정확하게 찾아내는 것이 매우 어렵거든요. 또한, 검색기는 사용자의 질문에 대해 적절한 컨텍스트를 제공하여 언어 모델이 보다 정확한 답변을 생성할 수 있도록 도와주기 때문에 검색기 성능은 RAG 시스템의 전반적인 효율성과 사용자 만족도에 직접적인 영향을 미친다고 볼 수 있죠.
동작 방식은 네 가지 과정으로 구분되는데요, 첫 번째는 질문의 벡터화입니다. 사전 준비 단계에서 언급했던 임베딩 단계와 유사한 기술을 사용해 사용자 질문을 벡터 형태로 변환하는데요, 변환된 질문 벡터는 후속 검색 작업의 기준점으로 사용돼요. 그 후 벡터 유사성을 비교하는 과정이 이루어지는데요, 저장된 문서 벡터들과 질문 벡터 사이의 유사성을 계산합니다. 주로 코사인 유사성(Cosine Similarity), Max Marginal Relevance(MMR) 등 수학적 방법이 사용되죠.
그 다음은 계산된 유사성 점수를 기준으로 상위 N개의 가장 관련성이 높은 문서를 선정하는 과정인데요, 이 문서들은 다음 단계에서 사용자의 질문에 대한 답변을 생성하는 데에 사용됩니다. 마지막 과정은 문서 정보를 반환하는 과정입니다. 선정된 문서들의 정보를 다음 단계(프롬프트)로 전달하는데요, 이 정보에는 문서의 내용, 위치, 메타 데이터 등이 포함돼요.
정보 검색 시스템에서 사용되는 두 가지 주요 방법이 있는데요, 문서와 쿼리(질문)를 이산적인 키워드 벡터로 변환하여 처리하는 Sparse Retriever와 최신 딥러닝 기법을 사용하여 문서와 쿼리를 연속적인 고차원 벡터로 인코딩하는 Dense Retriever가 있습니다. 이 두 가지 방법은 자연어 처리 분야, 특히 대규모 문서 집합에서 관련 문서를 검색할 때 사용돼요.
Sparse Retriever는 주로 텀 빈도-역문서 빈도(TF-IDF)나 BM25와 같은 전통적인 정보 검색 기법을 사용합니다. Sparse Retriever는 각 단어의 존재 여부만을 고려하기 때문에 계산 비용이 낮고, 구현이 간단하다는 특징이 있는데요, 하지만 단어의 의미적 연관성을 고려하지 않고, 검색 결과의 품질이 키워드 선택에 크게 의존한다는 리스크가 있습니다.
Dense Retriever는 문서의 의미적 내용을 보다 풍부하게 표현할 수 있고, 키워드가 완벽하게 일치하지 않더라도 의미적으로 관련된 문서를 검색할 수 있어요. 벡터 공간에서의 거리를 사용해 쿼리와 가장 관련성이 높은 문서를 찾는 방식이죠. 언어의 뉘앙스와 문맥을 이해하는 데에 유리하고, 복잡한 쿼리에 대해 더 정확한 검색 결과를 제공할 수 있다는 장점이 있습니다. 복잡한 질문이나 자연어 쿼리에 대해서는 Dense Retriever가, 간단하고 명확한 키워드 검색에는 Sparse Retriever가 더 유용할 수 있어요.
Prompt
Prompt 프롬프트
검색기 이후 단계는 바로 프롬프트입니다. 검색기에서 검색된 문서들을 바탕으로 언어 모델이 사용할 질문이나 명령을 생성하는 과정이에요. 이 단계는 검색된 정보를 바탕으로 최종 사용자의 질문에 가장 잘 대응할 수 있는 응답을 생성하기 위해 필수적인 단계입니다.
프롬프트는 언어 모델이 특정 문맥에서 작동하도록 설정하는 역할을 하는데요, 이를 통해 제공된 정보를 바탕으로 보다 정확하고 관련성 높은 답변을 생성할 수 있어요. 여러 문서에서 검색된 정보는 서로 다른 관점이나 내용을 포함할 수 있기 때문에 프롬프트 단계에서 이러한 정보를 통합하고, 언어 모델이 이를 효율적으로 활용할 수 있는 형식으로 조정하는 거죠. 응답 품질 향상에도 많은 영향을 미치는데요, 잘 구성된 프롬프트는 언어 모델이 보다 정확하고 유용한 정보를 제공할 수 있도록 도와줍니다. 프롬프트가 잘 구성되어 있지 않으면, 언어 모델이 비효율적으로 작동하고, 결과적으로 사용자의 요구에 부응하지 못하는 응답을 생성할 가능성이 높아지기 때문에 사용자의 질문에 최적화된 방식으로 응답을 생성하고, 시스템 전체의 성능과 사용자 만족도에 긍정적인 영향을 미칠 수 있는 프롬프트 엔지니어링이 중요합니다.
LLM
LLM Large Language Model
RAG 시스템의 일곱 번째 단계는 이전 프롬프트 단계에서 구성된 입력을 기반으로 대규모 언어 모델을 활용해 응답을 생성하는 과정입니다. 언어 모델의 능력을 최대한 활용해서 사용자의 질문에 대해 정확하고 자연스러운 답변을 생성하는 단계죠.
사용자의 의도를 이해하고, 문맥적 적응성을 갖는 데에 필수적인 단계라고 할 수 있어요. LLM은 다양한 언어 구조와 의미를 깊게 이해하고 있고, 이를 바탕으로 복잡한 질문에도 답을 할 수 있는데요, 자연어 이해(NLU)와 자연어 생성(NLG) 능력이 결합되어, 보다 자연스럽고 유익한 답변을 제공할 수 있고, 사전 학습된 지식 외에 사용자가 제공한 정보에 기반한 답변을 문맥을 참고해 답변할 수 있도록 하는 역할을 수행하죠.
이 단계는 사용자의 질문에 대한 답변의 질과 자연스러움을 결정짓는 핵심 요소에요. 이 단계에서 LLM은 지금까지의 모든 데이터와 정보를 종합해 사용자 질문에 최적화된 답변을 생성합니다.
Chain
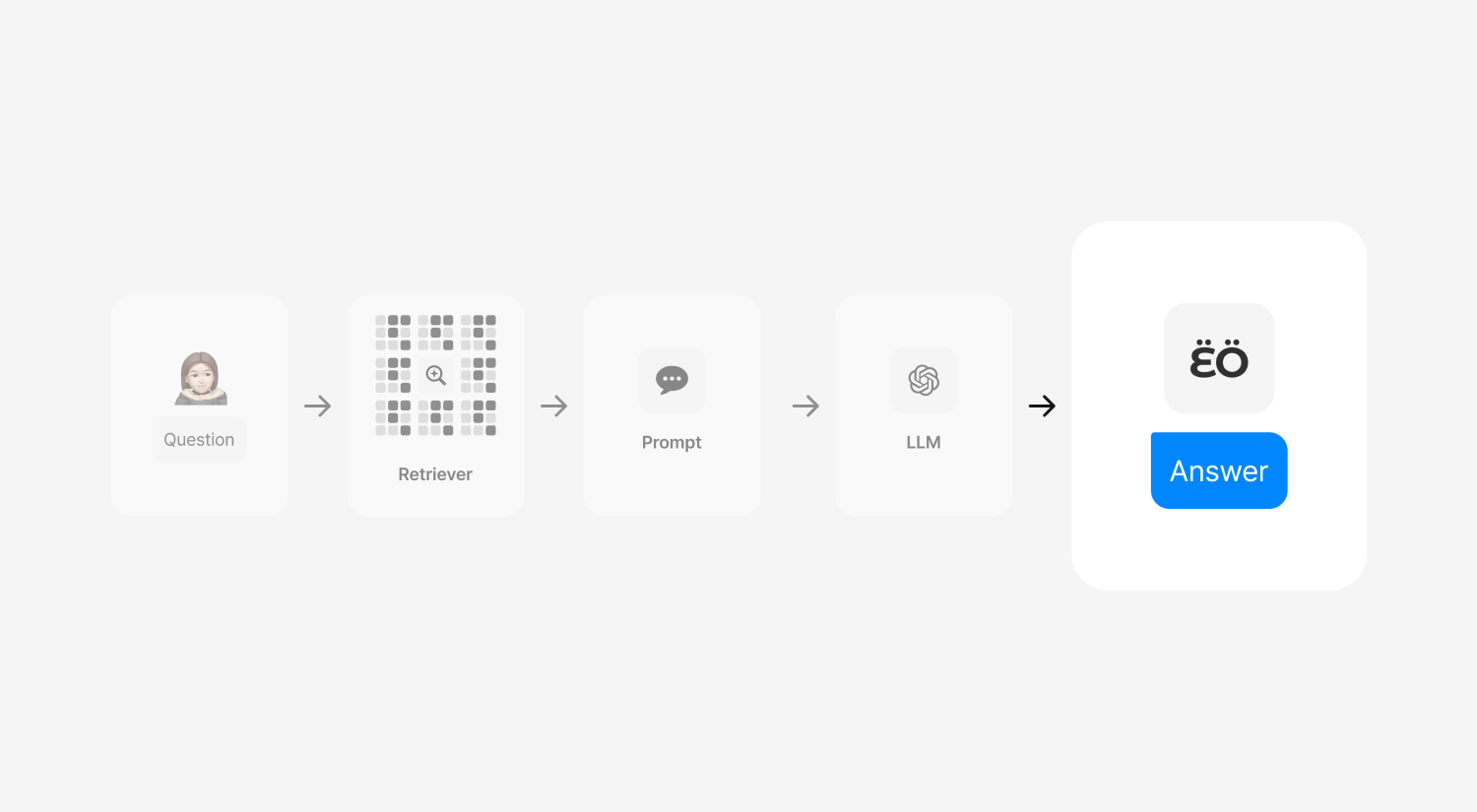
Chain 체인생성
RAG 시스템의 마지막 단계는 바로 Chain 생성 단계입니다. 이 단계는 이전의 7단계 과정을 모두 하나로 묶어 하나의 파이프라인으로 조립하여 완성하는 단계입니다.
Architecture of ËÖ
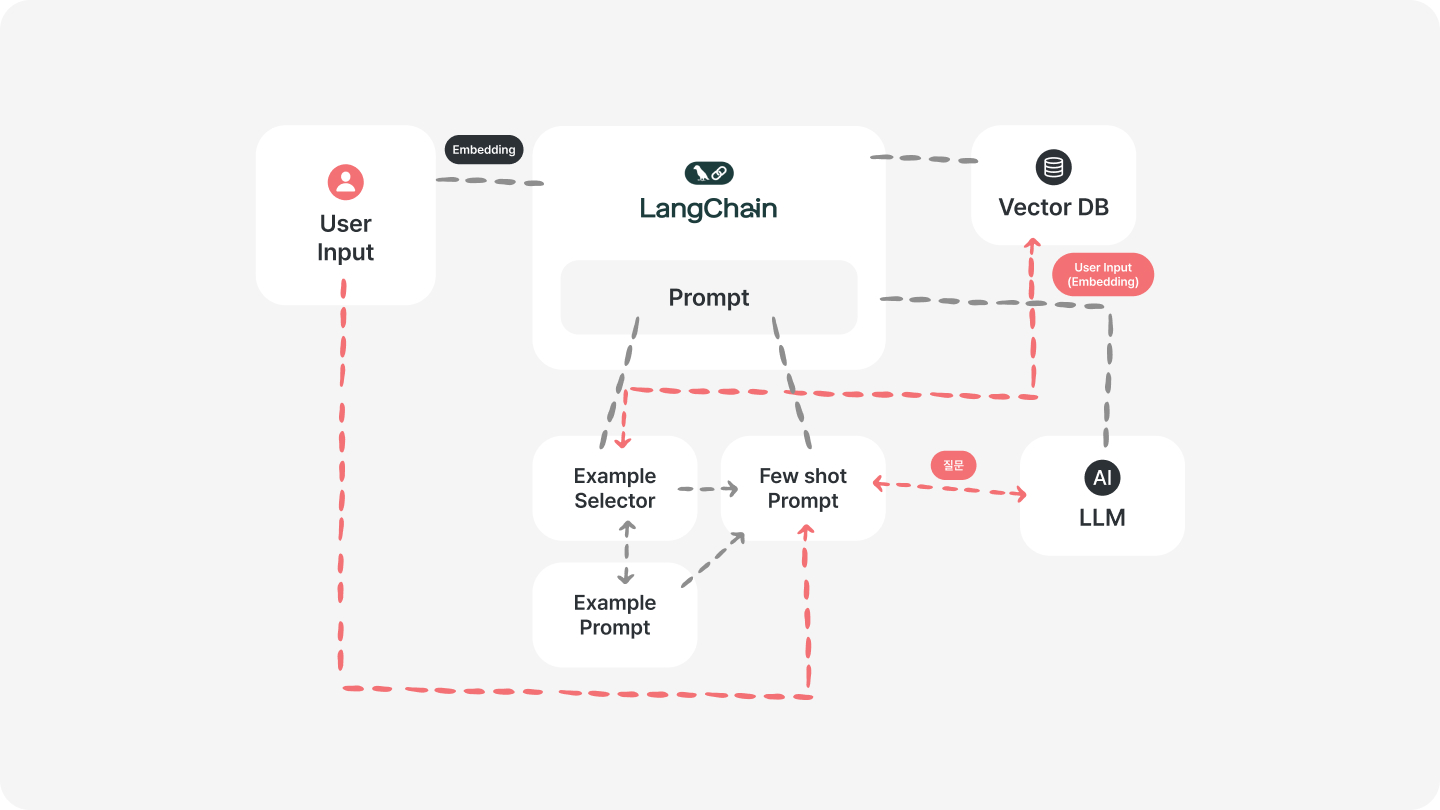
ËÖ가 동작하는 모습