
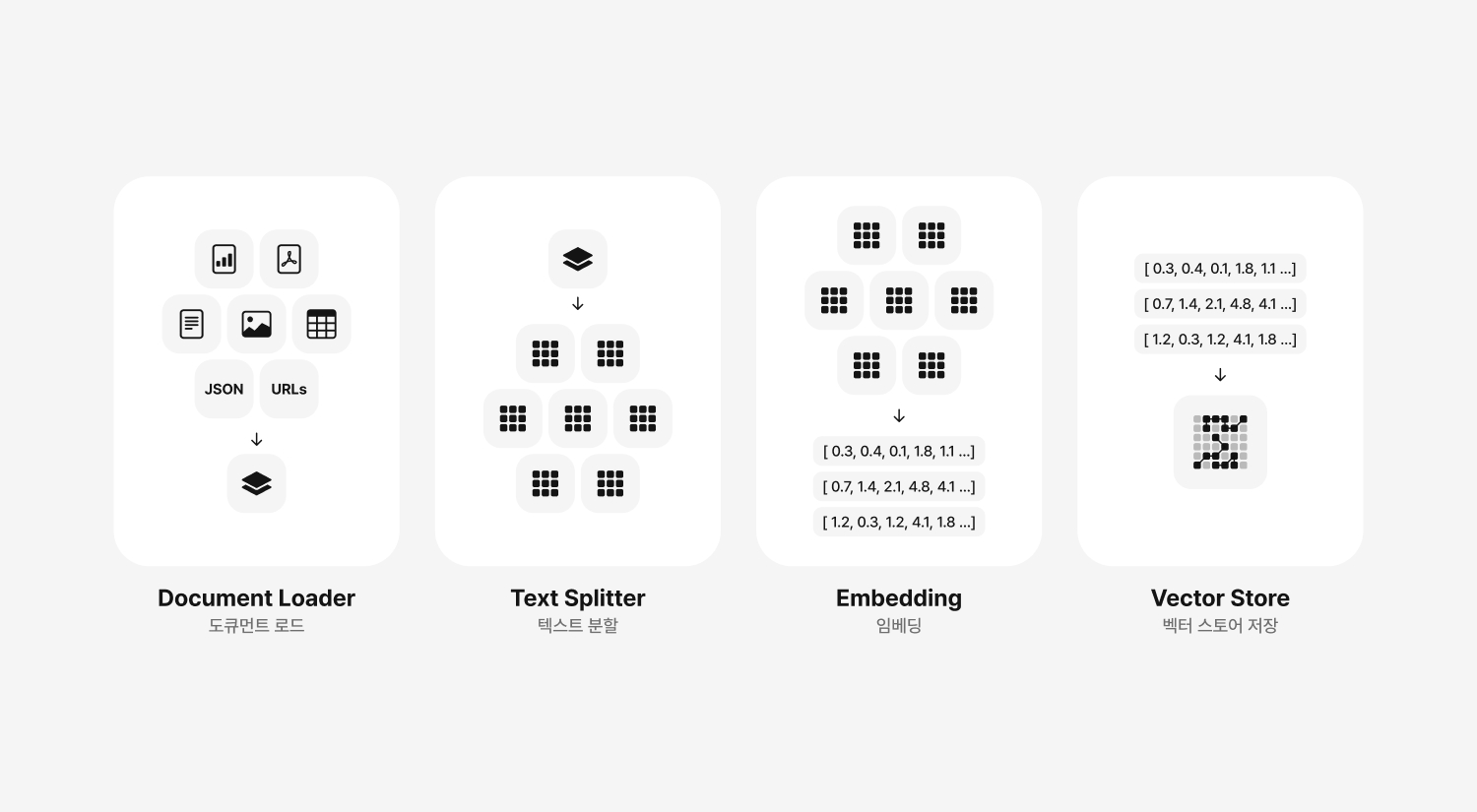
RAG 사전 준비 단계
Retrieval-Augmented Generation(RAG)는 자연어 처리(NLP) 분야에서의 혁신적인 기술로, 기존의 언어 모델의 한계를 넘어서는 정보 검색과 생성을 통합하는 방법론입니다. 기본적으로 RAG는 풍부한 정보를 담고 있는 대규모 문서 데이터베이스에서 관련 정보를 검색하고, 이를 통해 언어 모델이 더 정확하고 상세한 답변을 생성할 수 있게 도와주는데요, 예를 들어, 최신 뉴스 이벤트나 특정 분야의 전문 지식과 같은 주제에 대해 물어보면, RAG는 관련 문서를 찾아 그 내용을 바탕으로 답변을 구성하는거죠.
RAG는 크게 8단계의 프로세스로 구성되는데요, Document Loader(도큐먼트 로드), Text Splitter(텍스트 분할), Embedding(임베딩), Vector Store(벡터 스토어 저장)의 사전 준비 단계와 Retriever(검색기), Prompt(프롬프트), LLM(Large Language Model), Chain(체인 생성)의 런타임 단계로 나뉘어집니다. 그리고 이번 아티클에서는 사전 준비 단계에 대해서 설명드리려고해요.
사전 준비 단계
Document Loader
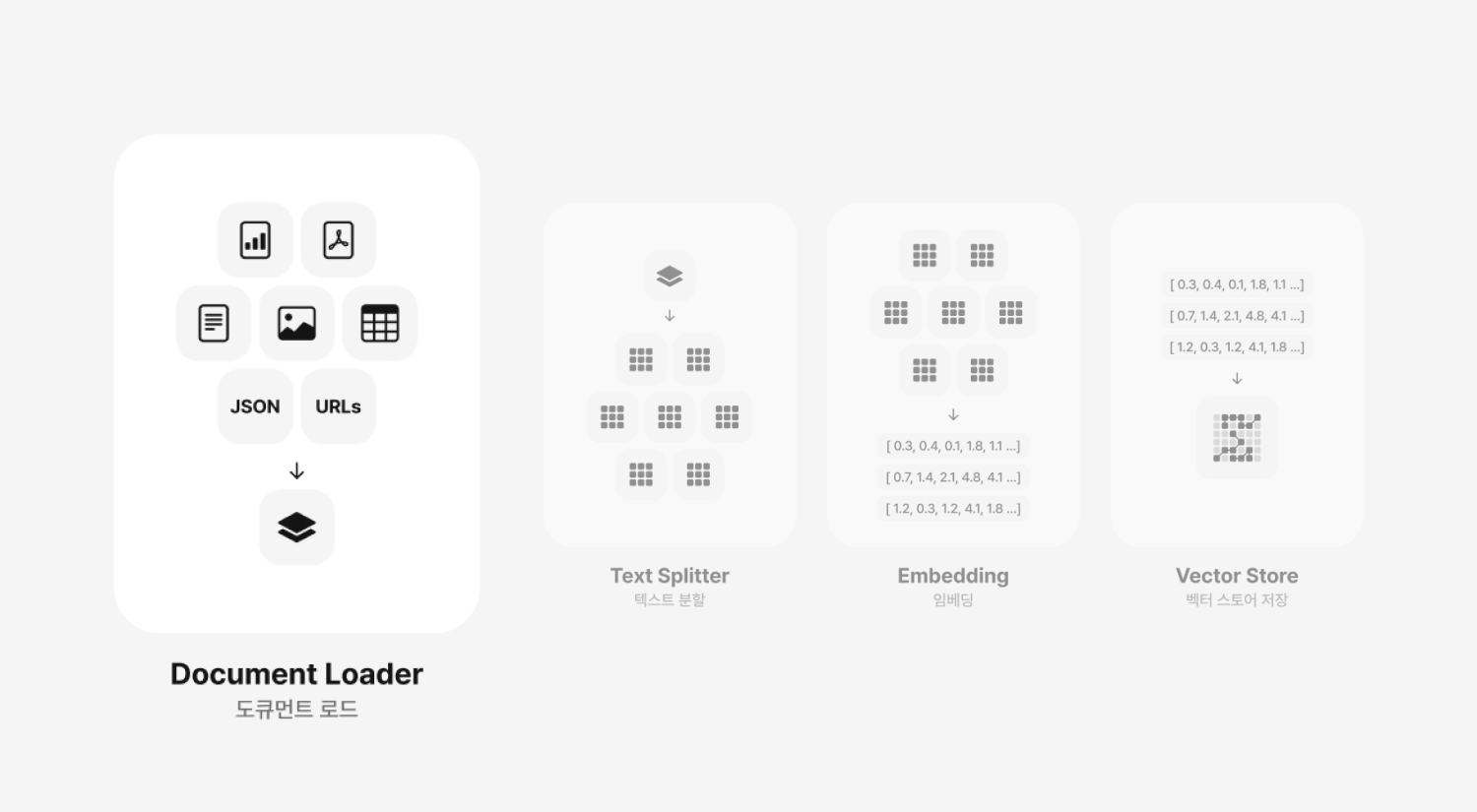
Document Loader 도큐먼트 로드
RAG 시스템의 첫 번째 단계로, 전체적인 프로세스에서 아주 중요한 기초 작업을 수행하는 단계입니다. 외부 데이터 소스에서 필요한 문서를 로드하고 초기 처리를 하는 단계죠. 도서관에서 다들 공부한 경험이 있으실텐데요, 공부하기 전에 필요한 책을 여러 권 챙겨서 공부하는 것과 비슷한 단계라고 생각하시면 됩니다. 공부하기 전에 필요한 책들을 책장에서 골라오는 과정이죠. 이 단계의 주된 목적은 RAG 시스템이 필요로 하는 데이터를 외부 소스로부터 효율적으로 수집하고 준비하는 것입니다.
먼저 어떤 종류의 데이터가 필요한지, 그리고 그 데이터를 어디서, 어떻게 수집할 지를 결정해야 하는데요, 데이터 소스는 웹, 데이터베이스, API 등 다양할 수 있습니다. 최신 뉴스 데이터가 필요하다면 실시간 뉴스 API나 크롤링을 사용할 수 있고, 과학적 논문이나 전문 지식이 필요하다면 학술 데이터베이스를 사용할 수 있죠.
위 과정이 결정되면 선택된 데이터 소스에서 필요한 데이터를 수집하는 작업이 진행됩니다. 이 과정에는 API 호출, 웹 스크래핑, 데이터베이스 쿼리 등을 포함할 수 있고, 인증이나 접근 권한 설정이 필요할 수도 있어요. PDF 문서, Word 또는 한글 문서, Excel, CSV, SQL Table, 마크다운 파일, HTML 문서 로드 등이 주요 작업에 포함됩니다.
이 과정이 끝나면 데이터 필터링과 전처리 과정이 진행되는데요, 수집된 데이터가 모두 필요한 정보는 아닐테니 RAG 시스템에서 필요한 정보만을 추출하고, 필요에 따라 데이터를 정제하는 과정을 거칩니다. 이 과정에서 불필요한 포맷팅을 제거하고, 언어나 문맥에 맞는 필터를 적용할 수도 있어요. 불필요한 이미지, 그래프, License 표기, 그 외 답변에 포함되지 말아야할 정보들을 제거하는 역할을 수행합니다.
위 과정이 모두 지나면 전처리된 데이터를 RAG 시스템 내부적으로 사용할 수 있는 형식으로 변환하고 로드하는 과정이 최종적으로 진행되는거죠. 뉴스 데이터를 로드하는 과정을 예로 들어볼게요.
RAG 시스템이 세계 뉴스에 대한 질문에 답변하기 위해 사용되는 경우, 신뢰할 수 있는 뉴스 서비스를 선택하고, API 혹은 크롤리을 통해 최신 뉴스 기사 데이터를 수집합니다. 그리고 수집된 기사 중 특정 주제에 해당하는 기사만을 선택하고, 필요없는 메타데이터 혹은 광고를 제거한 후 전처리된 뉴스 기사를 시스템의 데이터베이스에 저장하거나 직접 메모리로 로드하여 다음 처리 단계인 Text Splitter 단계로 넘어갑니다.
Text Splitter
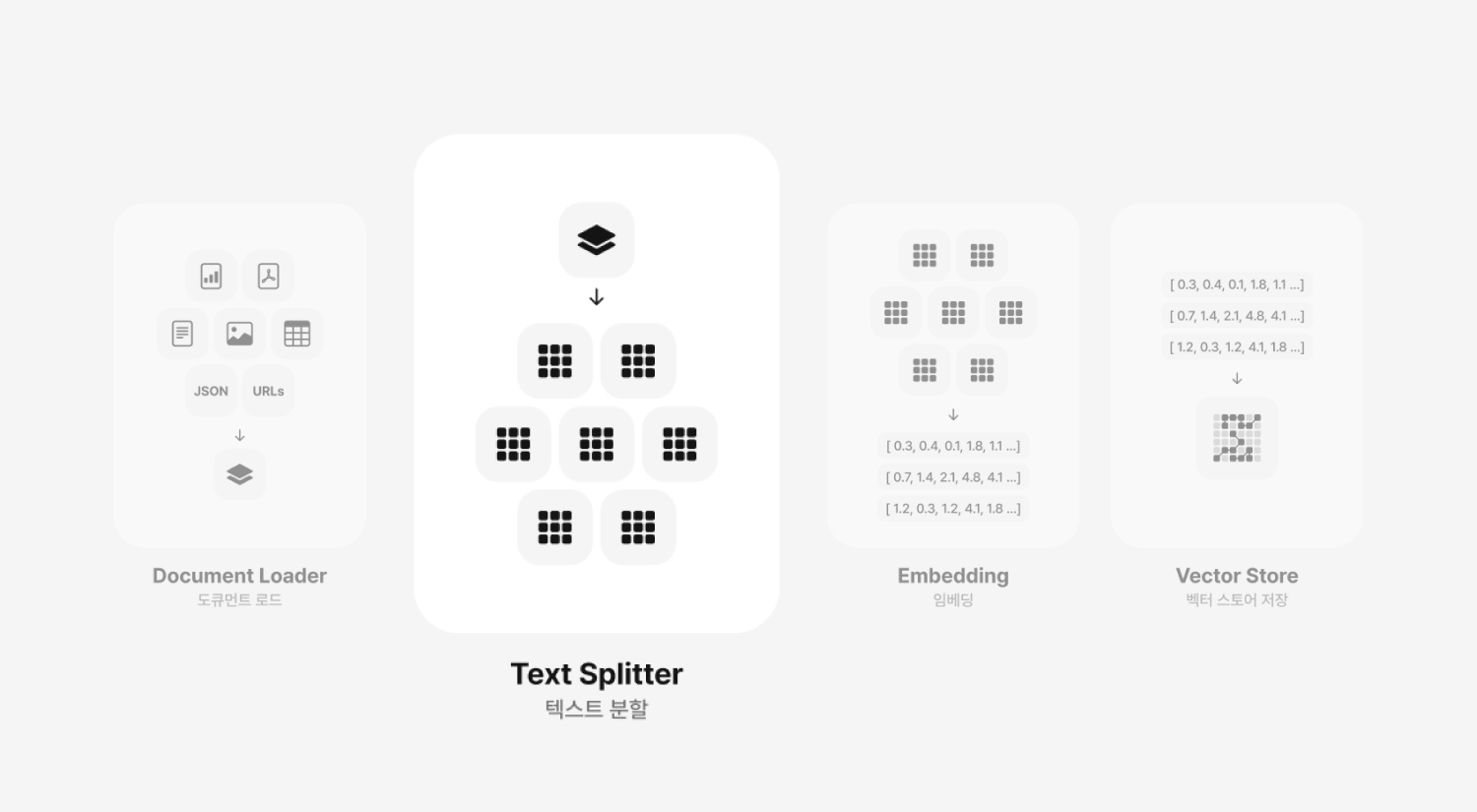
Text Splitter 텍스트 분할
텍스트 분할은 RAG 시스템의 두 번째 단계로, 로드된 문서들을 효율적으로 처리하고, 시스템이 정보를 보다 잘 활용할 수 있도록 준비하는 과정입니다. 도큐먼트 로드 과정을 ‘공부하기 전에 필요한 책들을 책장에서 골라오는 과정’이라고 설명했는데요, 텍스트 분할은 큰 책을 챕터별로 나누는 것과 같다고 생각하시면 될 것 같아요. 크고 복잡한 문서를 LLM이 받아들일 수 있는 효율적인 작은 규모의 조각으로 나누는 게 목적인 이 단계는 나중에 사용자가 입력한 질문에 대하여 보다 효율적인 정보만 압축하고, 선별하여 가져오는 데 중요한 역할을 하죠.
이 작업을 수행하는 이유는 두 가지가 있는데요, 첫 번째는 정확성입니다. 핀포인트 정보를 검색하는 거죠. 문서를 세분화함으로써 질문(Query)에 연관성 있는 정보만 가져오는 데에 도움이 됩니다. 각각의 단위는 특정 주제나 내용에 초점을 맞추기 때문에, 보다 관련성이 높은 정보를 제공합니다.
두 번째는 효율성입니다. 리소스를 최적화하기 위함이에요. 문서 전체를 LLM으로 입력하게 되면 많은 비용이 발생하고, 많은 정보 속에서 답변을 발췌하기 때문에 효율적인 답변을 하지 못해요. 그리고 이러한 문제가 할루시네이션으로 이어지기도 해요.
문서를 분할하는 데에는 4가지 과정으로 이루어지는데요, 문서 구조를 파악함으로써 첫 번째 과정이 시작됩니다. PDF, 웹 페이지 등 다양한 형식의 문서에서 구조를 파악합니다. 그 다음으로 어떤 단위로 나눌지를 결정하는데요, 페이지별, 섹션별, 또는 문단별로 나눌 수 있으며, 이는 문서의 내용과 목적에 따라 다르겠죠? 그 다음으로 문서를 몇 개의 토큰 단위로 나눌 것인지, 단위 크기(Chunk Size)를 선정하고, 최종적으로 분할된 끝 부분에서 맥락이 이어질 수 있도록 일부를 겹쳐서 분할하는 청크 오버랩(Chunk Overlap) 과정을 거칩니다.

Chunk Size & Chunk Overlap 청크 크기와 청크 오버랩 예시
Embedding
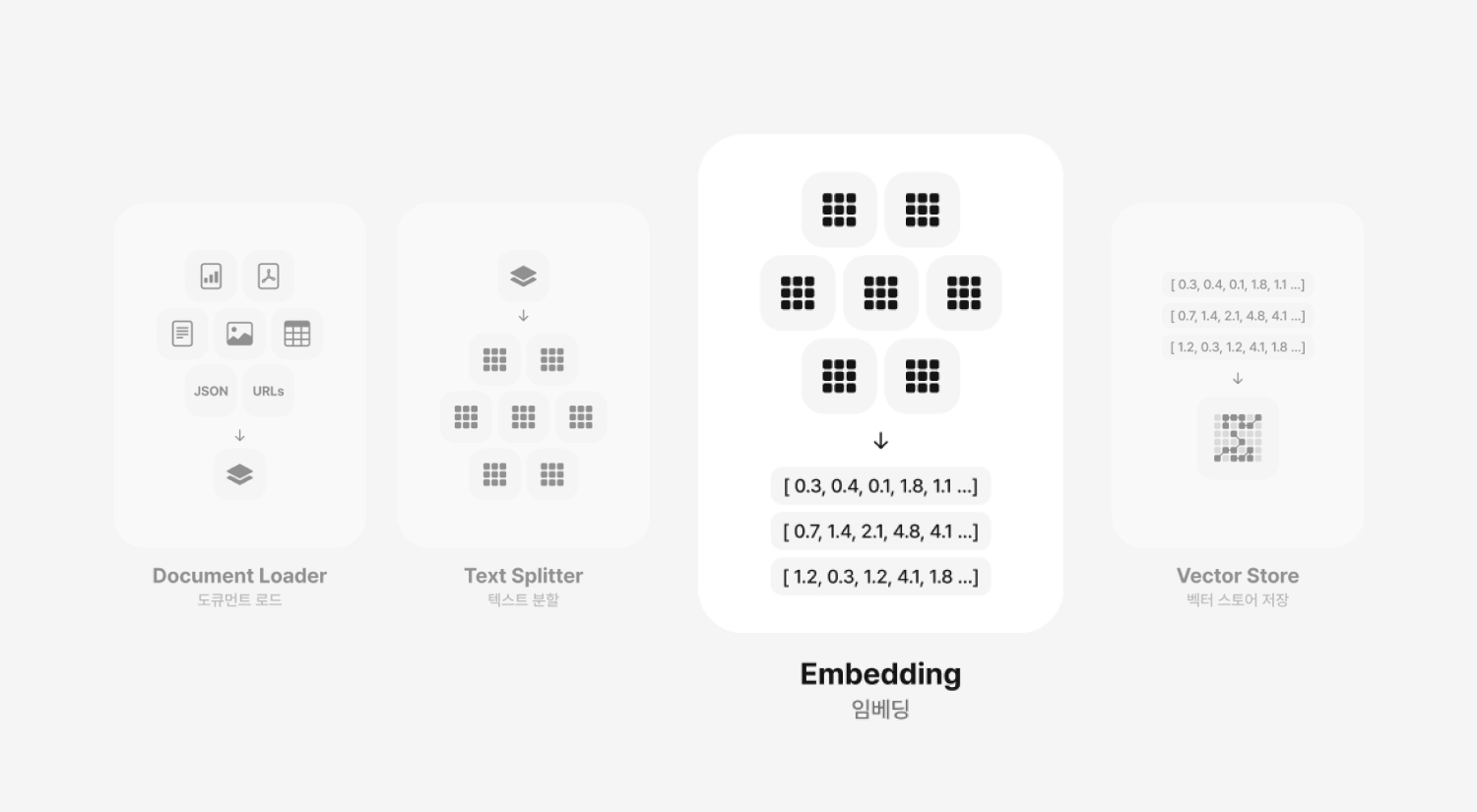
Embedding 임베딩
RAG 시스템의 세 번째 단계인 임베딩은 텍스트 분할 단계에서 생성된 단위들을 컴퓨터가 이해할 수 있는 수치적 형태로 변환하는 과정입니다. 텍스트의 의미를 숫자의 배열(벡터)로 표현함으로써, 사용자가 입력한 질문에 대해서 데이터베이스에 저장한 문서조각과 단락(Chunk)을 검색하여 가져올 때, 유사도 계산 목적으로 활용됩니다. 책의 내용을 요약하여 핵심 키워드로 표현한다고 말할 수 있겠네요.
수치화된 벡터 형태로 변환하는 임베딩 단계는 문서 간의 유사성을 계산하는 데에 있어 필수적인데요, 이는 관련 문서를 검색하거나, 사용자의 질문에 가장 적합한 정보를 찾는 작업을 용이하게 해요. 우리가 사용하는 자연 언어는 매우 복잡하고 다양한 의미를 내포하고 있어서, 임베딩을 통해 텍스트를 정량화된 형태로 변환해야 컴퓨터가 문서의 내용과 의미를 더 잘 이해하고 처리할 수 있습니다.
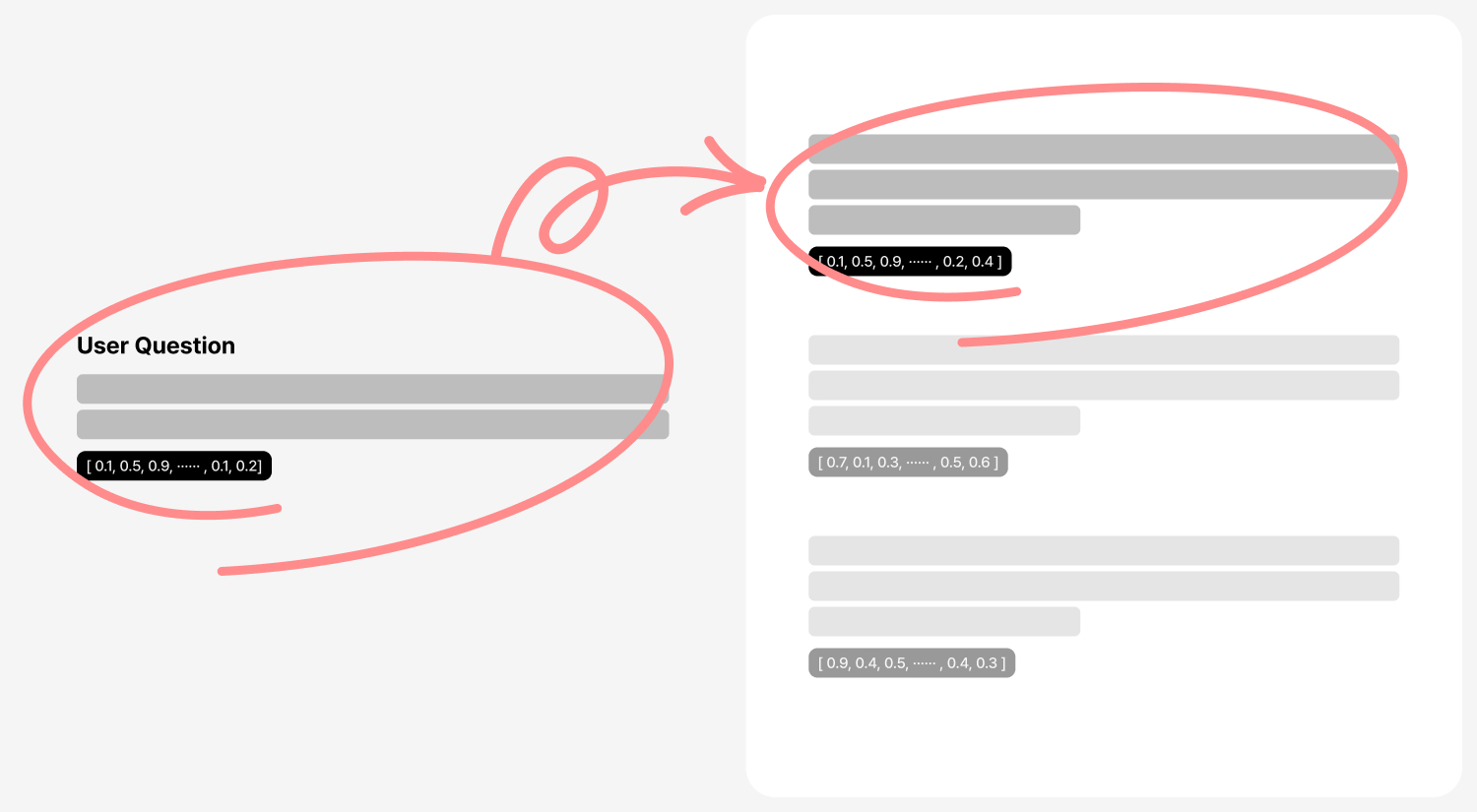
Cosine Similarity 코사인 유사도
Vector Store
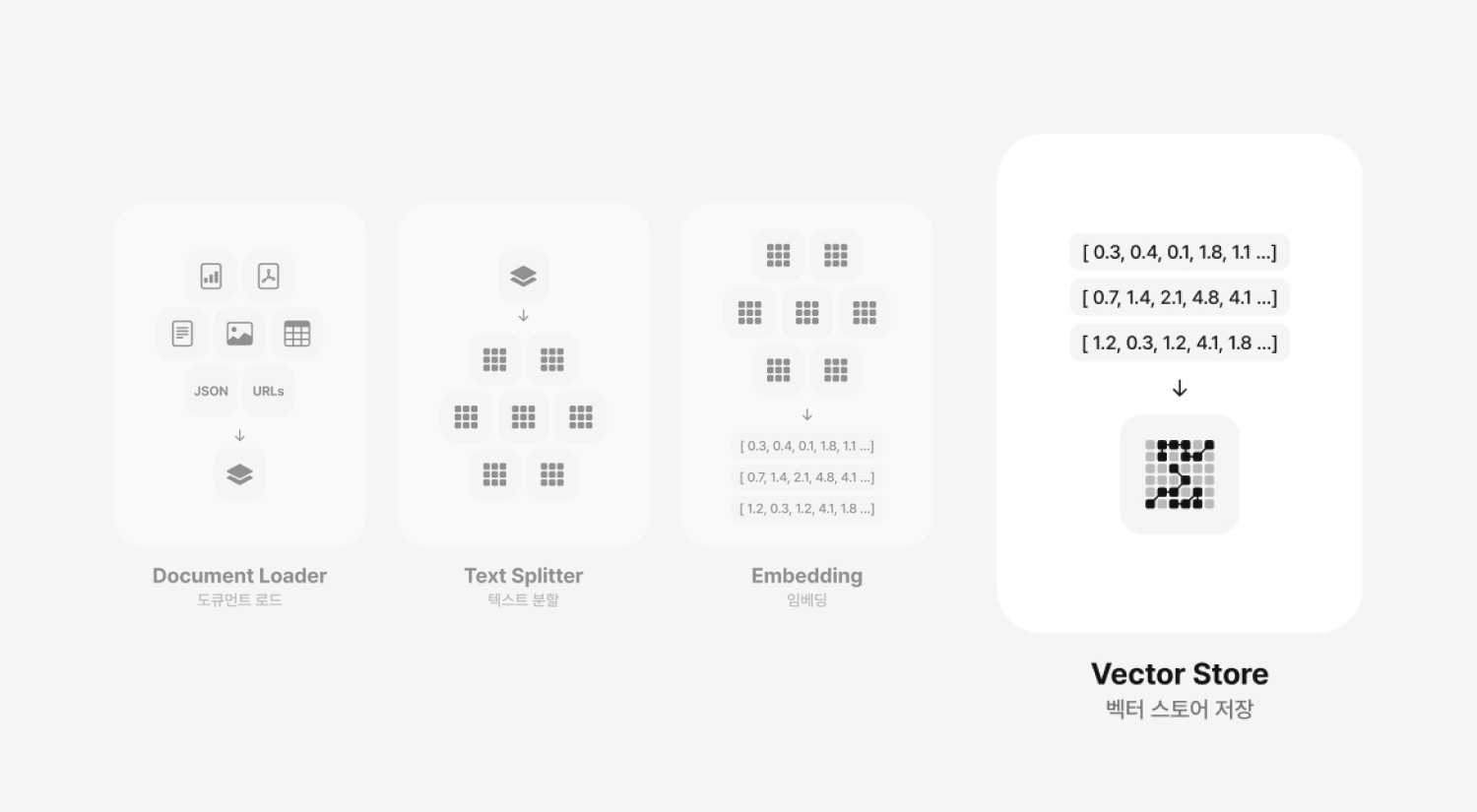
Vector Store 벡터스토어 저장